
![]()
Beside regular problem of Big Data analysis there is one more complex subtle task - persisting highly intensive data stream in a real-time. Image a scenario when your application cluster generates 100k business transactions per second, each one should be properly processed and written to data storage for further analysis and business intelligence reporting. Every transaction is also very precise and you can not lose any as it will cause data integrity constraints to be broken.
There are different message broker tools available to address this kind of scenario, like Apache Kafka, Amazon SQS or RabbitMQ. They do their job pretty well, but tend to be more general purpose and as such slightly bloated and time consuming for deployment needs.
In this article I would like to show how you can solve real-time data processing task simply and elegant with Apache Flume.
Flume design
Apache Flume is a distributed, reliable, and high available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralised data store.
Flume is simple and straightforward as name implies. You can configure it with .properties file and setup complex data flows in a distributed manner. For sake of our task we will configure Flume to get maximum real-time throughput out of it. We set it up to act as message broker between clustered java application and Hadoop HDFS raw data storage.
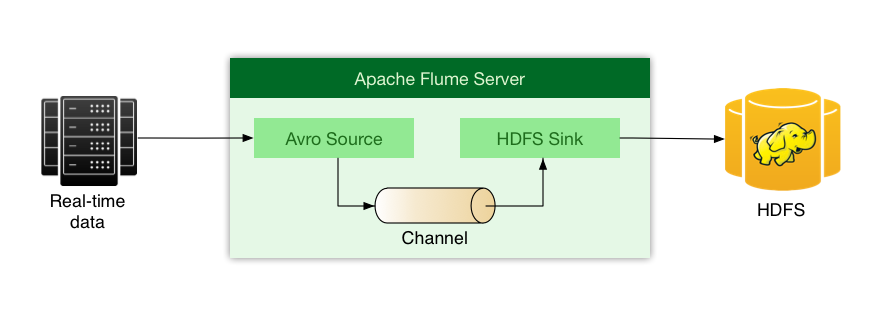
Every Flume data flow should have at least 3 main components: Source, Channel and Sink.
- Source receives data from external clients
- Channel aggregates data and pass to Sink
- Sink is responsible for writing data to external system.
Source could be any of following adapters: Avro, Thrift, JMS, Kafka. And Sink supports: HDFS, Avro, Thrift, Hive, Hbase, Elastic, Kafka, formats.
For our scenario we will configure Flume Server to receive Avro messages from multiple clients and write them to HDFS filesystem. See diagram below.
There are 2 main problems to address when trying to persist 100k mes/sec on single server node:
- Network/disk throughput (writing to HDFS)
- Handling data stream peaks resiliently
Configure for high throughput
We are going to solve throughput problem with batch processing, so Flume will aggregate specific number of messages into single batch when sending them to HDFS.
agent.sinks.hdfs.hdfs.rollCount = 300000
agent.sinks.hdfs.hdfs.batchSize = 10000
Here rollCount defines maximum number of messages which could be saved into single file on HDFS. And batchSize controls number of messages which are written to HDFS per single transaction. The more data we write per transaction to HDFS - less transactions we need, this decreases disk and network load.
Managing data stream peaks resiliently
Another problem is data flow peaks, say if throughput could rise up to 500k mes/sec for some short period of time. We need to tolerate such scenario by allocating some intermediate store to avoid out of memory exceptions.
agent.channels.c1.capacity = 1000000
agent.channels.c1.transactionCapacity = 10000
agent.channels.c1.type = memory
This could be achieved with Channel configured to store up to 1 million records received from Source before being written to Sink. It assures capacity size enough to preserve data growth level when Source is receiving records faster than Sink is able to write. It makes entire system behave resiliently under data stream peaks.
Next transactionCapacity parameters controls how many records are passed from Channel to Sink per transaction (could be equal to agent.sinks.hdfs.hdfs.batchSize). Making value higher makes less IO operations required to write the same amount of data.
If Channel needs to be fault tolerant and preserve messages in case of system failures there is option to set persistent storage on disk with parameter agent.channels.c1.type = file.
Here is complete listing of Flume Server configuration:
agent.sources = avro
agent.channels = c1
agent.sinks = hdfs
agent.sources.avro.type = avro
agent.sources.avro.channels = c1
agent.sources.avro.bind = 0.0.0.0
agent.sources.avro.port = 44444
agent.sources.avro.threads = 4
agent.sinks.hdfs.type = hdfs
agent.sinks.hdfs.channel = c1
agent.sinks.hdfs.hdfs.path = hdfs://cdh-master:8020/logs/%{messageType}/%y-%m-%d/%H
agent.sinks.hdfs.hdfs.filePrefix = event
agent.sinks.hdfs.hdfs.rollCount = 300000
agent.sinks.hdfs.hdfs.batchSize = 10000
agent.sinks.hdfs.hdfs.rollInterval = 0
agent.sinks.hdfs.hdfs.rollSize = 0
agent.sinks.hdfs.hdfs.idleTimeout = 60
agent.sinks.hdfs.hdfs.timeZone = UTC
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000000
agent.channels.c1.transactionCapacity = 10000