


Intro
This article shows how to get around all tough stuff related to Big Data infrastructure, how to work with data fast and comfortably, without thinking about code deployment, keeping focused on business goals and getting things done as quickly as possible. And Zentadata Platform is an answer. It is shipped with SDK that can be simply added to your java application so you can start developing Big Data applications right away.
Just for demo purposes we will build a pet Spring Boot microservice which will expose a few REST endpoints. Each of those will be triggering different big data tasks on Zentadata Cluster.

In our previous article related to Data Studio you can also read about how to work with multiple data sources and files, and how to join them together: Data analytics for everyone with Zentadata Data Studio.
Note: to install local developer cluster on your machine please read our Quick start guide 🚀 article.
Data analytics use case - RetailRocket dataset
We will start with some data first. I have found this public dataset https://www.kaggle.com/datasets/retailrocket/ecommerce-dataset which looked interesting to me. It contains reasonable amount of data so you can play with it locally using the Zentadata Developer edition. There is also information about the data structure and description on the mentioned site but just for this demo purposes and simplicity I will take events.csv file and will be working with it.
Allright, so let’s take a look into events.csv file, I will do it from Data Studio.
DataFrame events = zen
.read("localfs")
.format(DataFormat.CSV)
.option(CsvOpts.HAS_HEADER, "true")
.from("file:/home/dmch/datasets/RetailRocket/events.csv");
events.limit(5).execute().show();
OUTPUT:
+-------------+---------+-----+------+-------------+
|timestamp |visitorid|event|itemid|transactionid|
+-------------+---------+-----+------+-------------+
|1433221332117|257597 |view |355908|null |
|1433224214164|992329 |view |248676|null |
|1433221999827|111016 |view |318965|null |
|1433221955914|483717 |view |253185|null |
|1433221337106|951259 |view |367447|null |
+-------------+---------+-----+------+-------------+
As you can see and as per description from the web site this is the user's behavior data, i.e. events like clicks, add to carts, transactions - represent interactions that were collected over a period of 4.5 months.
Now actually I need to build a Spring Boot microservice which will have 4 REST endpoints that allow me to manipulate events and create different report types in my Postgres DB based on the data we have:
/api/events/{limit}- will be responsible for getting some number of events and send them back as a response/api/events/user/{userId}- will get all events of specific visitor/api/events/daily-report- will be responsible for generating daily report for a particular date/api/events/sales-report- will be responsible for generating sales reports for time interval, for this one data will be partitioned by date which is close to real life scenario with a lot of data
Create Spring Boot project
Let’s go https://start.spring.io/ pick up dependencies we need and create a project. Here is my setup:
After the project is downloaded, let’s add dependency to the Zentadata client library.
<repositories>
<repository>
<id>Zentaly</id>
<url>https://libs.zentaly.com</url>
</repository>
</repositories>
<dependency>
<groupId>com.zentadata</groupId>
<artifactId>client</artifactId>
<version>0.3</version>
</dependency>
Now pretty familiar stuff for each java developer who has ever worked with Spring Boot, let’s create Controller, Service etc. Here is my ReportsController:
@RestController
@RequestMapping("/api")
public class ReportsController {
private final ReportService reportService;
public ReportsController(ReportService reportService) {
this.reportService = reportService;
}
@GetMapping("/events/{limit}")
public List<Event> getEvents(@PathVariable int limit) {
return reportService.getEvents(limit);
}
@PostMapping("/events/user/{userId}")
public List<Event> getEventsByUserId(@PathVariable Long userId) {
return reportService.getEventsByUserId(userId);
}
@PostMapping("/events/daily-report")
public void generateDailyReport(@RequestParam @DateTimeFormat(pattern = "yyyy-MM-dd") Date date) {
reportService.generateDailyReport(date);
}
@PostMapping("/events/sales-report")
public void generateSalesReport(
@RequestParam @DateTimeFormat(pattern = "yyyy-MM-dd") Date fromDate,
@RequestParam @DateTimeFormat(pattern = "yyyy-MM-dd") Date toDate) {
reportService.generateSalesReport(fromDate, toDate);
}
}
Now we can do some real codding and implement each method of ReportService one by one.
Case #1 - get first N events from CSV file
We start with the simplest one - the getEvents method. We just simply need to get a number (limited by request parameter) of records from our events file and return back as a response. It’s quite simple.
First I need to specify the Zentadata Cluster connection properties (host, port, authentication details if needed etc).
ZenSession zen = new ZenSession("localhost", 8090);
Next we need to specify the DataFrame and where it should take data from and how to transform it if needed.
DataFrame events = zen
.read("localfs")
.format(DataFormat.CSV)
.option(CsvOpts.HAS_HEADER, "true")
.from("file:/home/dmch/datasets/RetailRocket/events.csv");
And the implementation for getEvents method which will simply collect the data and return it as a server response.
public List<Event> getEvents(int limit) {
return events
.limit(limit)
.execute()
.getPayload(Event.class);
}
So that’s it, let’s start our app, go to the terminal and check the result.
curl -s -X GET "http://localhost:9090/api/events/2" | jsonpp
[
{
"timestamp": "2015-06-02T05:02:12.117+00:00",
"visitorid": 257597,
"event": "view",
"itemid": 355908,
"transactionid": 0
},
{
"timestamp": "2015-06-02T05:50:14.164+00:00",
"visitorid": 992329,
"event": "view",
"itemid": 248676,
"transactionid": 0
}
]
Case #2 - get all events for a specific visitor
Now we want to limit events to the ones which belong to a specific user.
This could be done using where opearator (pretty similar to SQL language).
public List<Event> getEventsByUserId(Long userId) {
return events
.where(col("visitorid").equalTo(userId))
.execute()
.getPayload(Event.class);
}
Note: please notice that we use equalTo operator for comparision and not standard == operator. In fact our java application defines data processing job with this DSL statement, while actual heavy data processing runs on Zentadata Cluster.
Case #3 - generate events daily report
Let’s do something different now, but first of all a couple of words how Zentadata Platform works. As you might assume the volume of data can be huge, so you will not be able to download it into the java heap and do some manipulations with it. You simply get out of memory and your application fails.
That’s why all data processing is performed on Zentadata Cluster. So our java microservice can run on a tiny server with small amount of CPU and RAM, and process terrabytes of data on a cluster.
In our case, generating daily report might give us a huge amount of data. So instead of loading data into java heap, i will store it to the relational database. Later on that report can be used for UI or other downstream consumers, pretty standard approach.
Again using zentadata sql-like language it’s pretty much simple and straightforward:
public void generateDailyReport(Date date) {
long from = date.getTime();
long to = date.getTime() + 24 * 60 * 60 * 1000;
DataFrame report = events.where(col("timestamp").geq(from)
.and(col("timestamp").leq(to)));
report.write("postgres")
.option(SaveMode.KEY, SaveMode.OVERWRITE)
.to(format("daily_report_%s", dateFormatForTableName.format(date)));
}
That’s actually it, you see that I have added one where clause and as a second step we write selected data to the postgres DB to the daily_report_<date> table. If that table does not exist it will be created automatically and each re-run of this operation (triggering REST endpoint in our case) will overwrite data.
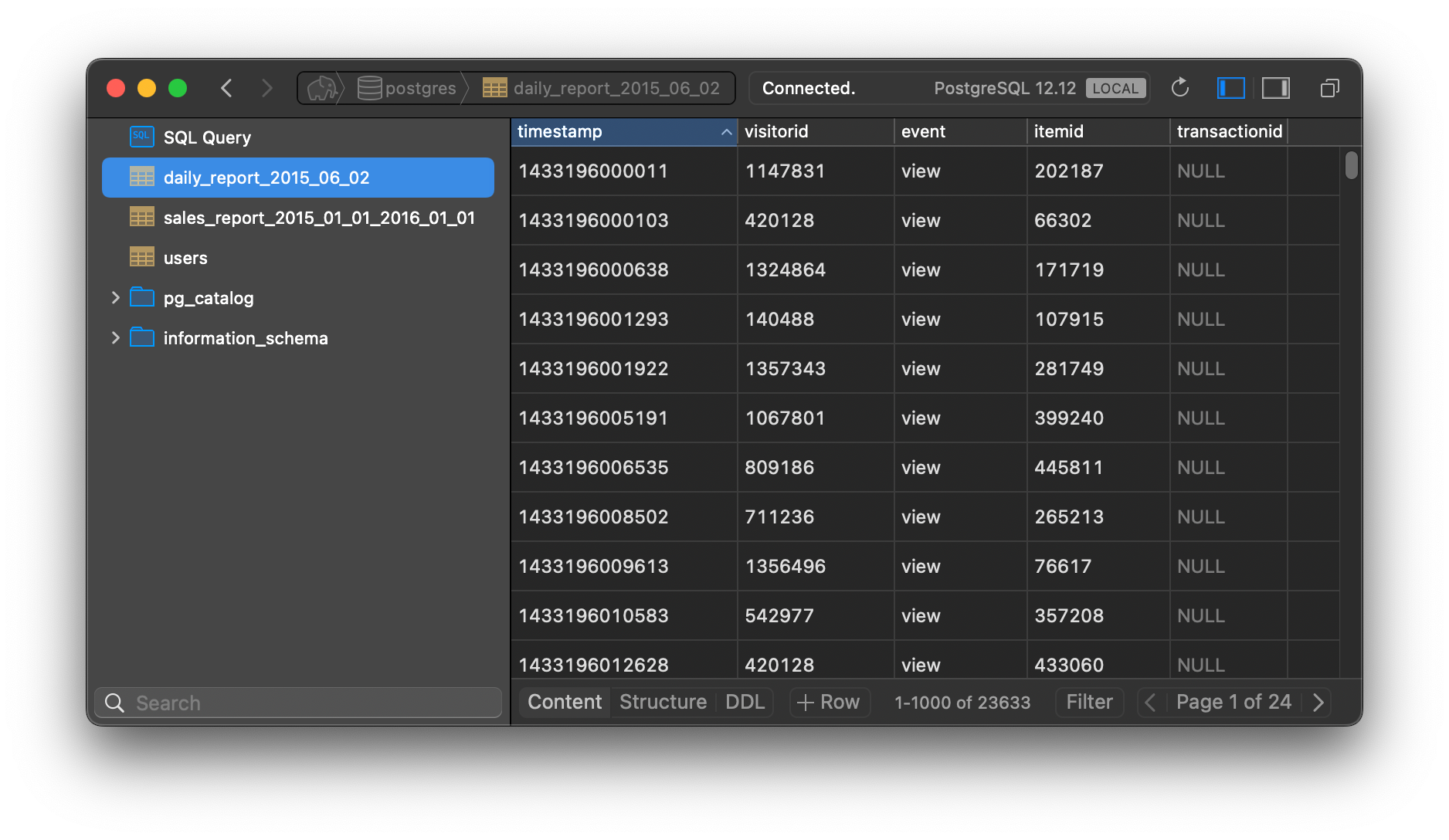
Lets call /api/events/daily-report endpoint and provide a report date. After successfull execution we will find a new table created in postgres daily_report_2015_06_02.
curl -X POST "http://localhost:9090/api/events/daily-report" -d "date=2015-06-02"
Case #4 - generate total sales report
Now let’s take a look at more real examples of data processing. I made some data preparation for the mentioned dataset - partitioned events.csv by date. So now I have a folder for each date, something like on the screenshots below. As a result we have data for 139 days, around 3 millions events and 1.5 millions unique visitors.
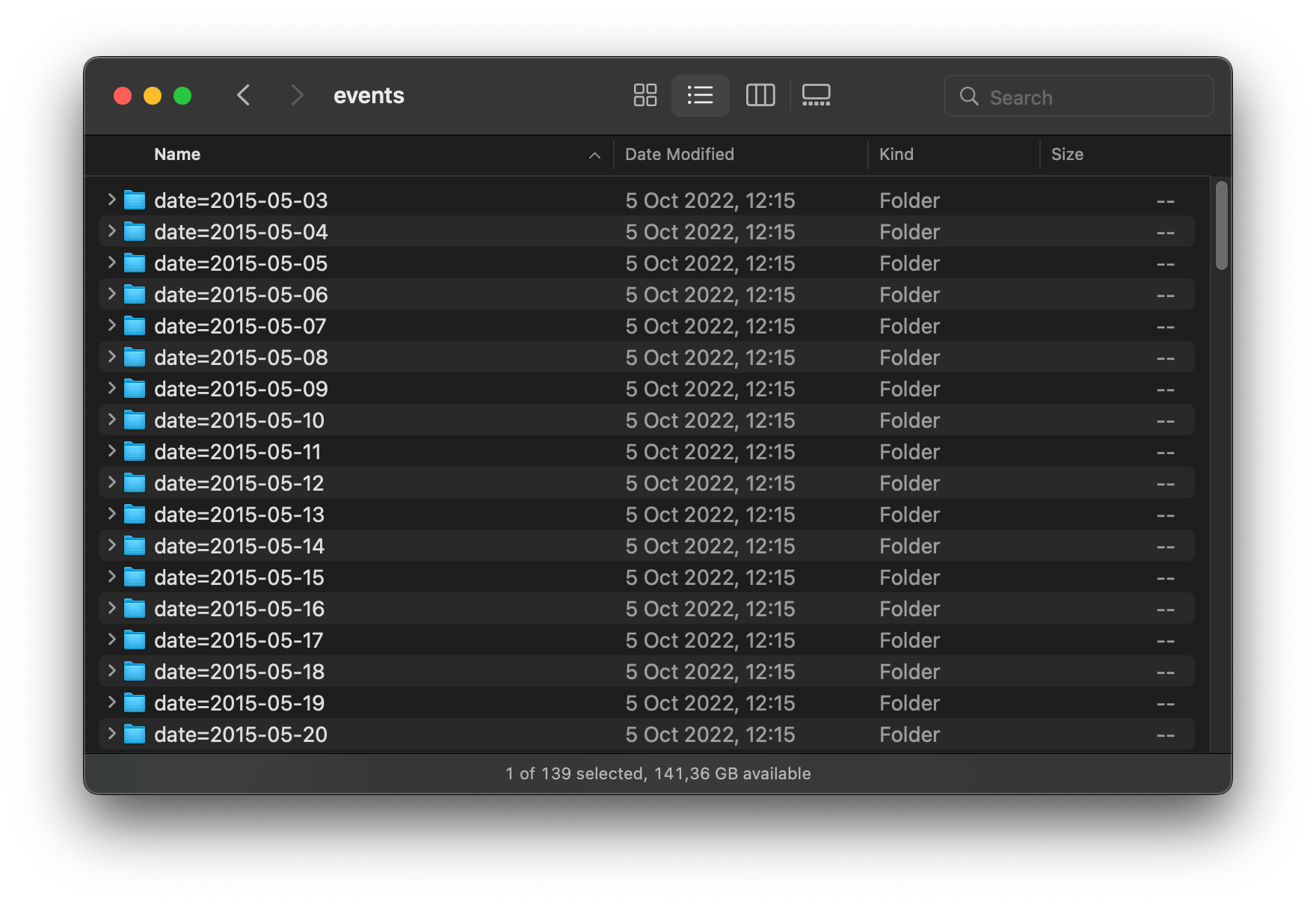
Note: In a real life partitioning is very important technique to deal with a big data. Some of our clients are generating terrabytes of data every day in distributed filesystems like HDFS or AWS S3. Storing data in a separate folders helps to decrease amount of data to be processed when we need to analyze just limited time window (day/week/month). Otherwise, if data will be stored as a single folder, we will have to do a full scan even when only one specific day should be analyzed.
In our case we can mimic partitioning using a local filesytem, as it is totally similar to enterprise grade distributed data storages.
public void generateSalesReport(Date fromDate, Date toDate) {
new Thread(() -> {
long from = fromDate.getTime();
long to = toDate.getTime();
DataFrame report = zen
.read("localfs")
.format(DataFormat.CSV)
.option(CsvOpts.HAS_HEADER, "true")
.from("file:/home/dmch/datasets/RetailRocket/events/*/*.csv"))
.where(col("event").equalTo("transaction")
.and(col("timestamp").geq(from))
.and(col("timestamp").leq(to)))
.select(col("timestamp"),
col("visitorid"),
col("itemid"));
report.write("postgres")
.option(SaveMode.KEY, SaveMode.OVERWRITE)
.to(format("sales_report_%s_%s",
dateFormatForTableName.format(from),
dateFormatForTableName.format(to)));
}).start();
}
From application developer perspective and code, it does not matter how the data is partitioned, or where it’s stored, our code remains almost the same as long as it has a similar format.
You only need to take into consideration the performance which will depend on the partitioning approach and amount of data. That script might take a while to be executed so we trigger this job in a separate thread and give the REST response right away saying that job is submitted for the execution. After the triggering our REST endpoint the work will be done by cluster and we get sales_report_* table created.
Please note that you can specify the destination to the data on the file system using regex patterns. That’s exactly how we defined that we are going to read all csv files inside all subfolders of the data/event folder.
Summary
We went through a few cases that might give you an understanding of how the platform allows to work with Big Data using standard Java and Spring stack. What is more, there is no need to build any sort of pipelines in order to ship the code to the cluster, you just need to grab the client library, make configuration once and work with data right away.
Of course there are a lot of other possible business cases and scenarios that can be covered with the flexibility of the platform design and available features. We are going to keep writing about them so you don’t have any doubts of getting started with Zentadata.